Create a Local AI Agent with n8n, Ollama, and Qdrant
Do you want to interact with your documents using artificial intelligence without relying on the cloud? In this post, we will show you step by step how to configure and use n8n, Ollama, and Qdrant to create local artificial intelligence (AI) agents that can read files from your computer or Google Drive and answer questions about their content. We will use Docker to simplify the process and ensure that everything works efficiently.
Running local AI agents offers total control and privacy, but also presents challenges such as hardware requirements and manual configurations. In this guide, we will help you overcome those barriers and experiment with practical workflows.
Advantages and Disadvantages
Using local AI agents with n8n has benefits and limitations. Here is a summary so you can make an informed decision:
| Advantages 🟢 | Disadvantages |
|---|---|
| Total privacy: Your data does not leave your machine. | High hardware requirements: You need a machine with good RAM and CPU. |
| No recurring costs: You don’t depend on external APIs or subscriptions. | Complex configuration: Requires manual installation and basic Docker knowledge. |
| Offline availability: Works without the internet, ideal for offline environments. | Manual maintenance: Updates and adjustments must be made manually. |
| Flexibility: You can customize flows and models according to your needs. | Resource consumption: It can be intensive in terms of CPU, RAM, and storage. |
| Integration with tools: n8n allows you to easily connect with other apps. | Learning curve: Requires familiarity with n8n, Ollama, and vector databases like Qdrant. |
Prerequisites
Before starting, make sure you have the following:
- Adequate hardware:
- Minimum 8 GB of RAM (16-32 GB recommended for better results).
- Modern CPU; a GPU is not strictly necessary, but improves performance.
- Docker : Necessary to manage containers.
- Docker Desktop ️: To run Docker on Windows, macOS, or Linux.
- Git: To clone repositories from GitHub.
- Basic knowledge of terminal and file editing.
note
The success of this guide will depend on your hardware. It will not be a problem if you have a powerful machine, but if not, you may experience slowness or errors.
Configuration of n8n, Ollama, and Qdrant
This guide details how to install and configure a local environment to chat with documents using n8n, Ollama, and Qdrant, all managed through Docker.
- n8n : Low-code/no-code automation tool that connects applications and processes data.
- Ollama : Platform to run language models locally (such as Llama 3.1/3.2 or DeepSeek).
- Qdrant ️: High-performance vector database to store and search documents.
Docker facilitates installation, Ollama serves the AI models, and Qdrant stores the vectorized documents so that n8n agents can query them.
1. Installation Options:
There are two starter kits that facilitate the installation of the necessary tools. Both kits include valuable components, but option B offers a better configuration that we will explain later.
2. Installation (Option B - Recommended):
As mentioned above, we recommend Option B for its more complete tool set, including n8n, Ollama, Qdrant, and PostgreSQL.
- Nvidia GPU
- Mac
- Others
For Nvidia GPU users
git clone [https://github.com/coleam00/ai-agents-masterclass.git](https://github.com/coleam00/ai-agents-masterclass.git)
cd ai-agents-masterclass/local-ai-packaged
# Modify the .env file (see step 3)
docker compose --profile gpu-nvidia upFor Mac / Apple Silicon users
If you are using a Mac with an M1 processor or newer, unfortunately you cannot expose your GPU to the Docker instance. In this case, there are two options:
- Run the starter kit entirely on the CPU, as in the “For everyone else” section below.
- Run Ollama on your Mac for faster inference, and connect to it from the n8n instance.
If you want to run Ollama on your Mac, see the Ollama home page for installation instructions, and run the starter kit as follows:
git clone [https://github.com/coleam00/ai-agents-masterclass.git](https://github.com/coleam00/ai-agents-masterclass.git)
cd ai-agents-masterclass/local-ai-packaged
# Modify the .env file (see step 3)
docker compose upAfter following the quick start setup below, change the Ollama credentials using http://host.docker.internal:11434/ as the host.
For everyone else
git clone [https://github.com/coleam00/ai-agents-masterclass.git](https://github.com/coleam00/ai-agents-masterclass.git)
cd ai-agents-masterclass/local-ai-packaged
# Modify the .env file (see step 3)
docker compose --profile cpu upFor Nvidia GPU users
git clone [https://github.com/coleam00/ai-agents-masterclass.git](https://github.com/coleam00/ai-agents-masterclass.git)
cd ai-agents-masterclass/local-ai-packaged
# Modify the .env file (see step 3)
docker compose --profile gpu-nvidia upFor Mac / Apple Silicon users
If you are using a Mac with an M1 processor or newer, unfortunately you cannot expose your GPU to the Docker instance. In this case, there are two options:
- Run the starter kit entirely on the CPU, as in the “For everyone else” section below.
- Run Ollama on your Mac for faster inference, and connect to it from the n8n instance.
If you want to run Ollama on your Mac, see the Ollama home page for installation instructions, and run the starter kit as follows:
git clone [https://github.com/coleam00/ai-agents-masterclass.git](https://github.com/coleam00/ai-agents-masterclass.git)
cd ai-agents-masterclass/local-ai-packaged
# Modify the .env file (see step 3)
docker compose upAfter following the quick start setup below, change the Ollama credentials using http://host.docker.internal:11434/ as the host.
For everyone else
git clone [https://github.com/coleam00/ai-agents-masterclass.git](https://github.com/coleam00/ai-agents-masterclass.git)
cd ai-agents-masterclass/local-ai-packaged
# Modify the .env file (see step 3)
docker compose --profile cpu up3. Configuration of the .env file:
After cloning the repository, in the local-ai-packaged folder, you will find a file called .env.example.
- Copy this file and rename it to
.env(delete.example). - Open the
.envfile with a text editor (Visual Studio Code is recommended). - This file contains passwords for the tools, although it is not necessary to modify them for this tutorial, it is important to know the default credentials for future use.
4. Verification in Docker Desktop
- Open Docker Desktop and verify that all containers (n8n, Ollama, Qdrant, PostgreSQL) and images have been installed correctly.
- If any container fails, check the logs in Docker Desktop.
5. Running the Containers
- In Docker Desktop, check if all containers are running.
- If any container is not running, start it manually.
- Make sure the n8n, Ollama, Qdrant, and PostgreSQL containers are running.
6. n8n Access
- Once the containers are running, open your browser and go to
http://localhost:5678(the default n8n port). - If this is your first time accessing, you will be asked to create a user account.
- Create a local account (email and password) the first time you log in.
Workflow Configuration in n8n
In this tutorial, you will learn how to create workflows in n8n to interact with local documents and also with documents in Google Drive. We will generate two workflows:
- AI Agent for Local Files (Local RAG): Allows you to upload files from your computer and chat with them.
- AI Agent for Google Drive (Google Drive RAG): Allows you to monitor and process files from a Google Drive folder.
AI Agent for Local Files (Local RAG)
This flow allows you to upload files from your computer and chat with them through n8n.
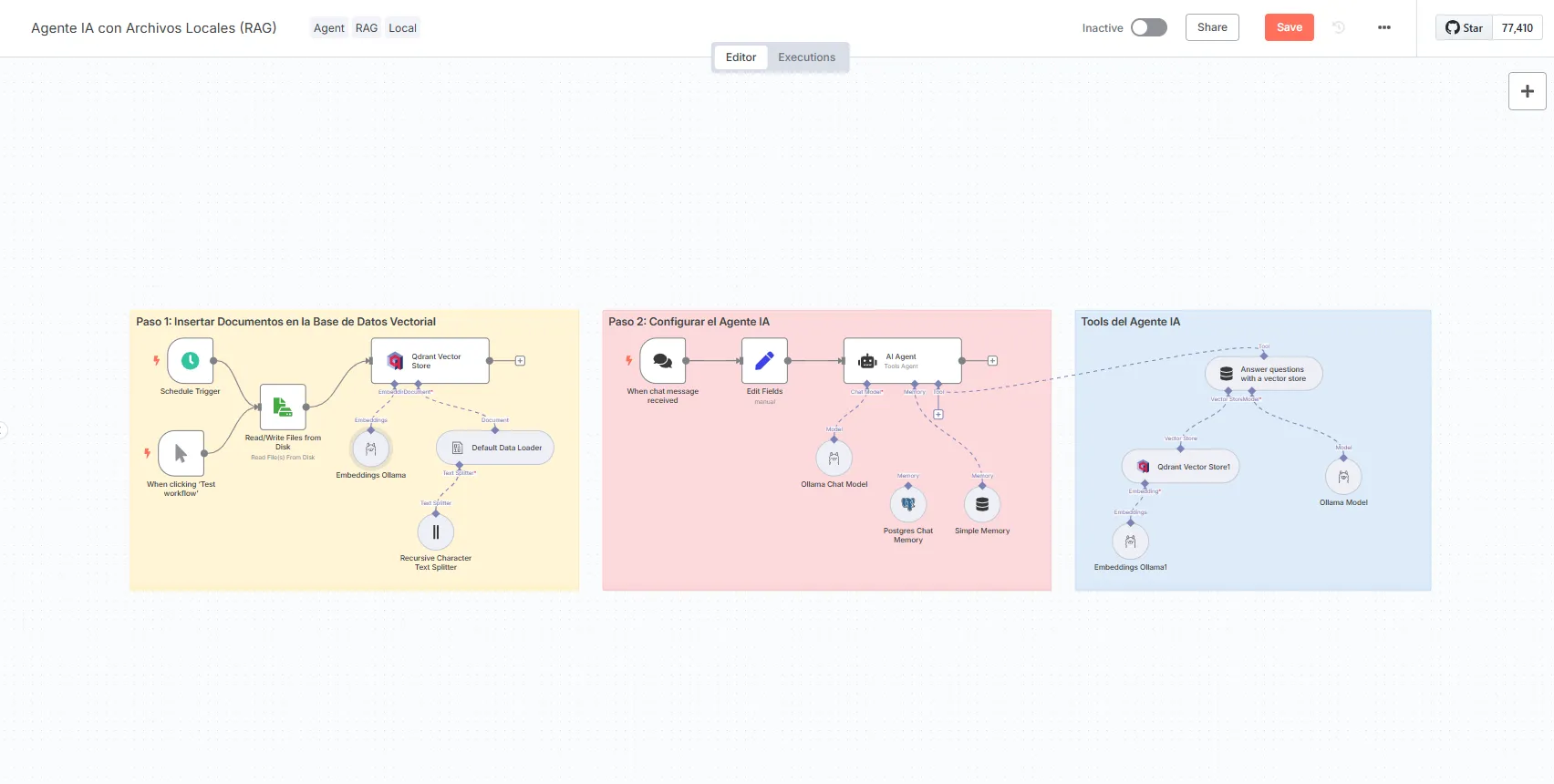
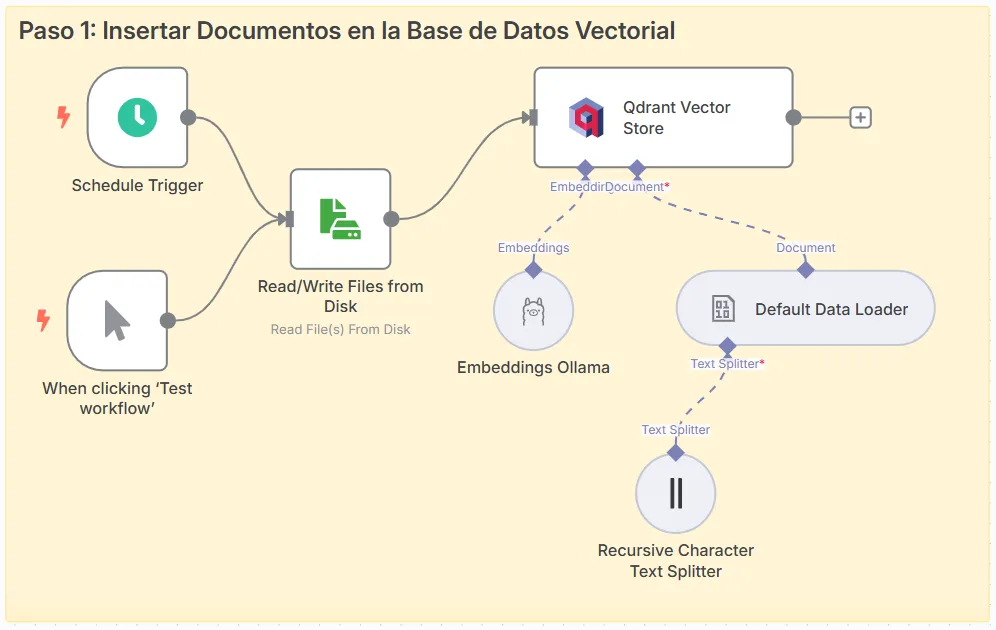
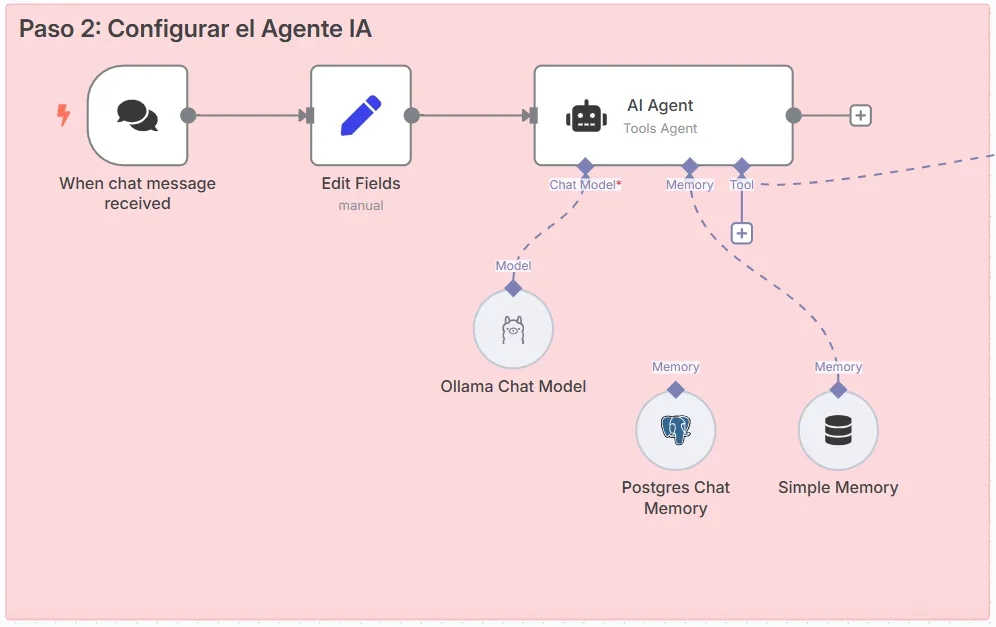
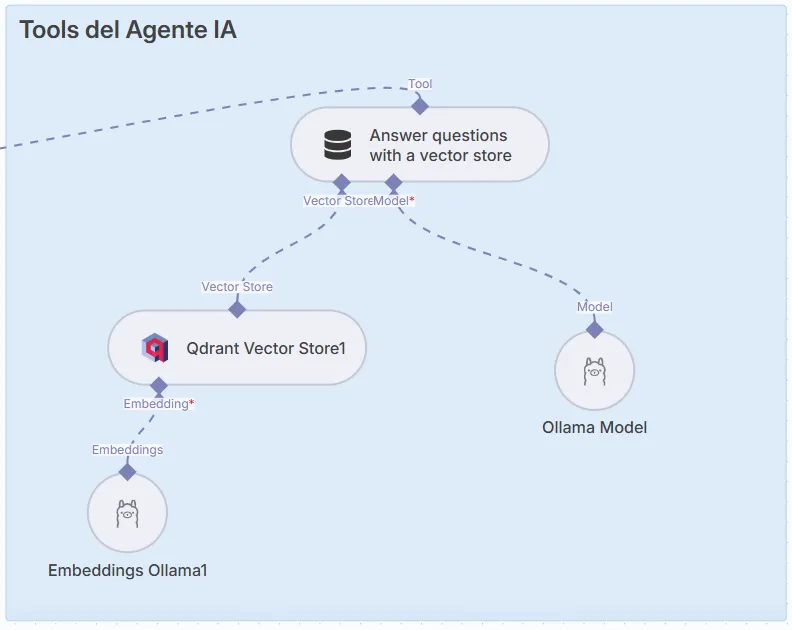
Steps:
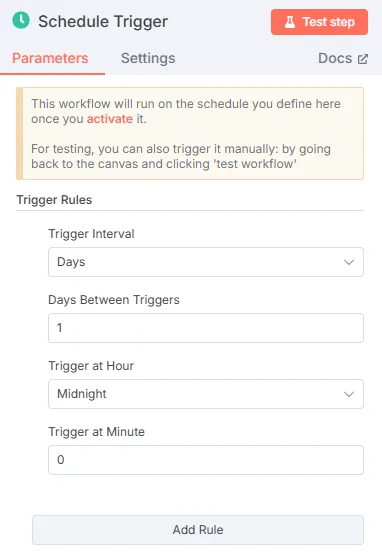
- Trigger Node: Start the flow. Use a “Schedule Trigger” or “Manual Trigger” for testing.
-
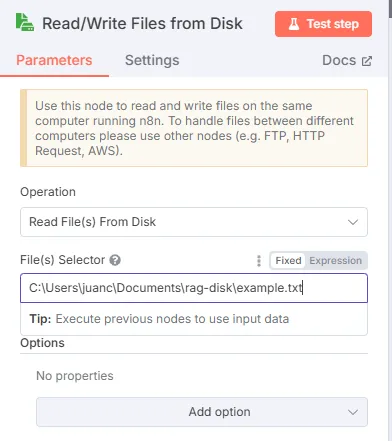
File Reading Node: Configure a “Read/Write Files” node to read local files.
- Operation: “Read Files”.
- Select the folder where your documents are (for example, PDFs, text, etc.).

-
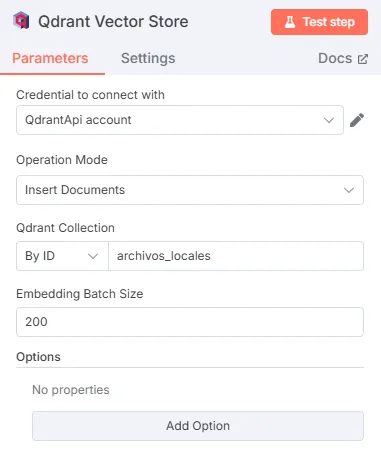
Qdrant Vector Store Node: Stores the documents in Qdrant.
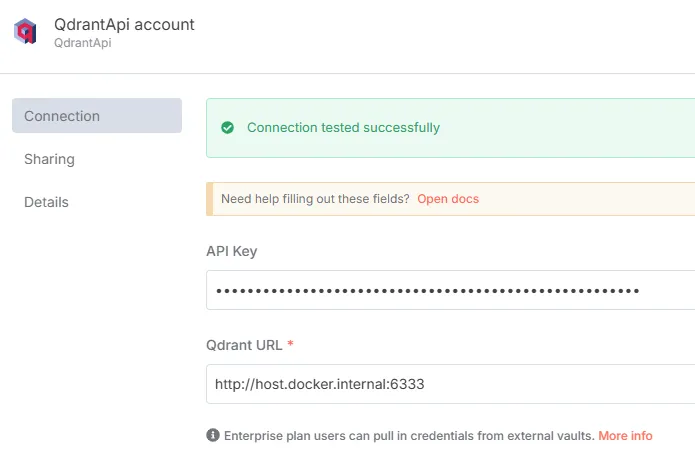
-
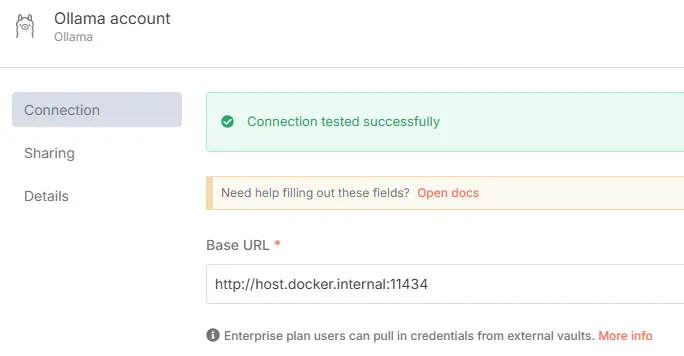
Configure Qdrant credentials (API Key and host, default
http://host.docker.internal:6333). -
Mode: “Insert Documents”.
-
Collection: Name it, for example, “local_files”.

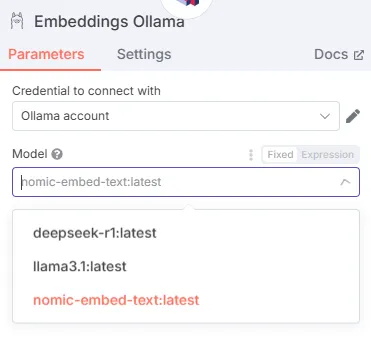
- Embeddings Node (Ollama): Converts the text to vectors.
-
Use the “nomic-embed-text” model from Ollama.
-
Host:
http://host.docker.internal:11434.
info
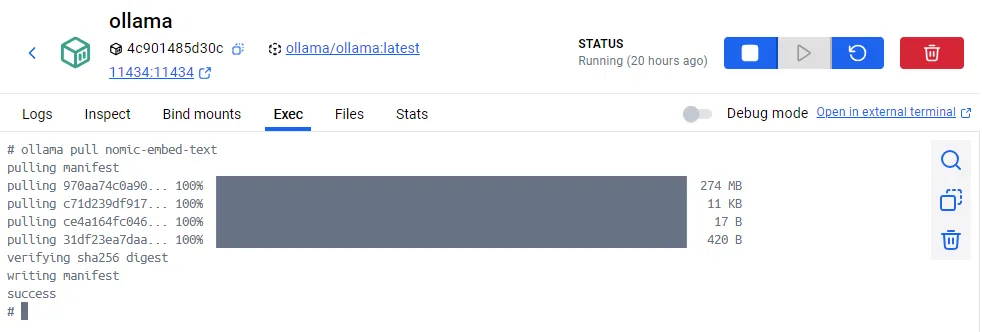
To download the embeddings model, run the following command in the terminal of
the Ollama container in Docker Desktop:
ollama pull nomic-embed-text
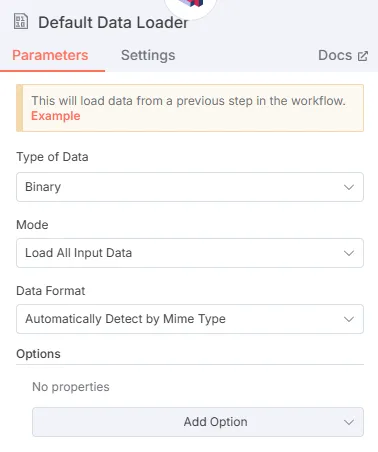
- Default Data Loader Node: Loads the data into Qdrant.
- Type: “Tools Agent”.
- Chat model: Select a local model such as “Llama 3.2” or “DeepSeek R1” from Ollama.
- Memory: Use “Window Buffer Memory” (5 messages by default) or PostgreSQL for persistence.
- Tool: Configure access to Qdrant to extract information.
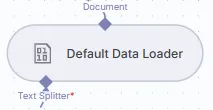
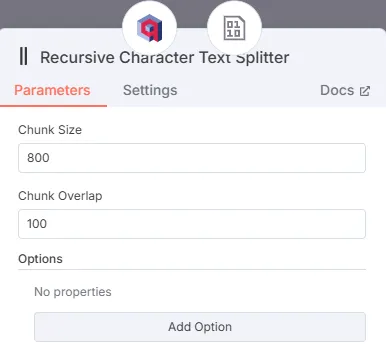
- Text Splitter Node: Divides the text into smaller parts.

- Testing:
-
Run the flow manually in n8n.
-
Use the chat in n8n to send questions (for example, “What is this document about?”).
-
Verify in Qdrant (access
http://host.docker.internal:6333/dashboard) that the documents have loaded correctly.
AI Agent for Google Drive (Google Drive RAG)
This flow allows you to monitor and process files from a Google Drive folder.
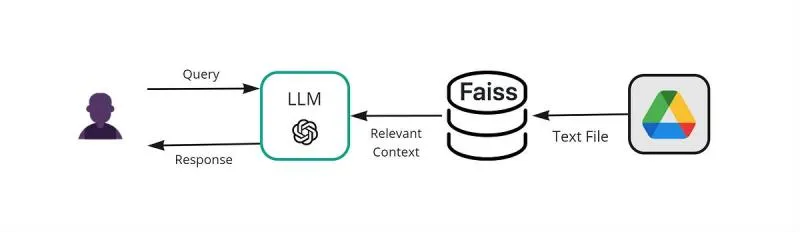
Steps:
- Trigger Node (Google Drive): Configure a trigger to detect new or updated files.
- Event: “File Created” or “File Updated”.
- Folder: Select your folder in Google Drive (for example, “n8n_demo”).
- Processing Nodes:
- “Edit Fields”: Extracts the file ID and folder.
- “Code Node”: Verifies and removes duplicates in Qdrant (code provided by the kit).
- File Download: Use a “Google Drive” node to download the file.
- Configure credentials in Google Cloud Console (Client ID and Secret).
-
Storage in Qdrant: Similar to the local flow, use Qdrant to store the vectorized documents.
-
AI Agent: Configure an agent similar to the previous one, but with the “documents_drive” collection in Qdrant.
-
Testing:
- Upload a file (for example, a PDF) to your Google Drive folder.
- Verify in Qdrant that the collection has been created.
- Use the chat in n8n to interact with the document.
Additional Considerations
- AI Models: We recommend using models such as Llama 3.1 (7B parameters) or Llama 3.2 (3B parameters). Performance depends on your hardware.
- Optimization: Divide the documents into chunks of 800 characters with an overlap of 100 for best results.
- Security: Everything is executed locally, but make sure to protect access to Docker and n8n.
With this configuration, you can create local AI agents that process documents efficiently, whether from your computer or from Google Drive, without the need for an internet connection or external services.